Sorting It All Out
I have a lot of images from the United States Holocaust Memorial Museum already. It’s about time I start looking through them to see what information I can get. The first issue I ran into, besides the shear number of them, is how to tell which images to look at first. Chronologically would be the best, but how to tell which document image is chrnologically first when they all have a generic file name. When I took the images at USHMM, they were automatically names liked so:
- KIC000294.jgp
- KIC000295.jpg
- KIC000296.jpg
- KIC000297.jpg
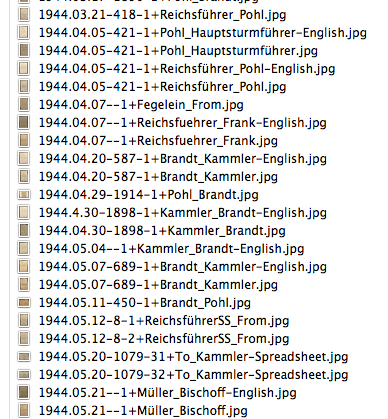
Not very descriptive, to say the least. I needed a way to see which documents came first in the time line of events, so I started thinking up a format for naming the images that would automatically sort the images, but also provide needed information. Since most of the files are images of correspondence between individuals, I decided to have the “To” and “From” be part of the file name. The date is also and obvious inclusion for the file name. Starting with the year, then month, then day makes it easy to sort the images chronologically. But what about documents written on the same day, and documents with mutiple pages? There’s a way to incorporate that too. So here is the naming scheme that I settled on for these document images.
Year.Month.Day-DocumentNumber-PageNumber+To_From-Description Year = The last two digits of the year Month = The two digit month Day = The two digit day Document Number = Each Nazi document seems to have a number, seemingly assigned when written/typed Page Number = The page number, if only one page, use 1. To = To whom the document is written. If not known, use 'To'. From = Who wrote the document. If not known, use 'From' Description = English (for English translation), Spreadsheet, Chart, Graph, etc
This allows me to see briefly what kind of document the file contains at a glance.
Thinking Ahead (programatically)
In an effort to show my skills as a digital historian… Ah, shucks, I’m not kidding anyone there. If you notice the naming format, you’ll see some odd use of word separators, or the fact that I use word separators at all instead of just spaces. That’s my programming mind coming to the fore there. I work with servers, all of them use Linux. Linux is OK with spaces in file names, but life is sooooooo much easier when there are none. So, here I’m thinking ahead to what I’m going to do with these images. Their new names are not just pretty to look at, but they will help me later on when I want to manipulate large numbers of them. With certain word separators in the name, it will be relatively easy to write a script that will search through all of the files and be able to parse out the dates, names, document numbers, page numbers, and descriptions. This info can be put into a CSV file for easy editing and adding information in a SpreadSheet program, which can then later be uploaded to Omeka. So just by taking care to name the files correctly will save me a lot of time later down the road.
One comment