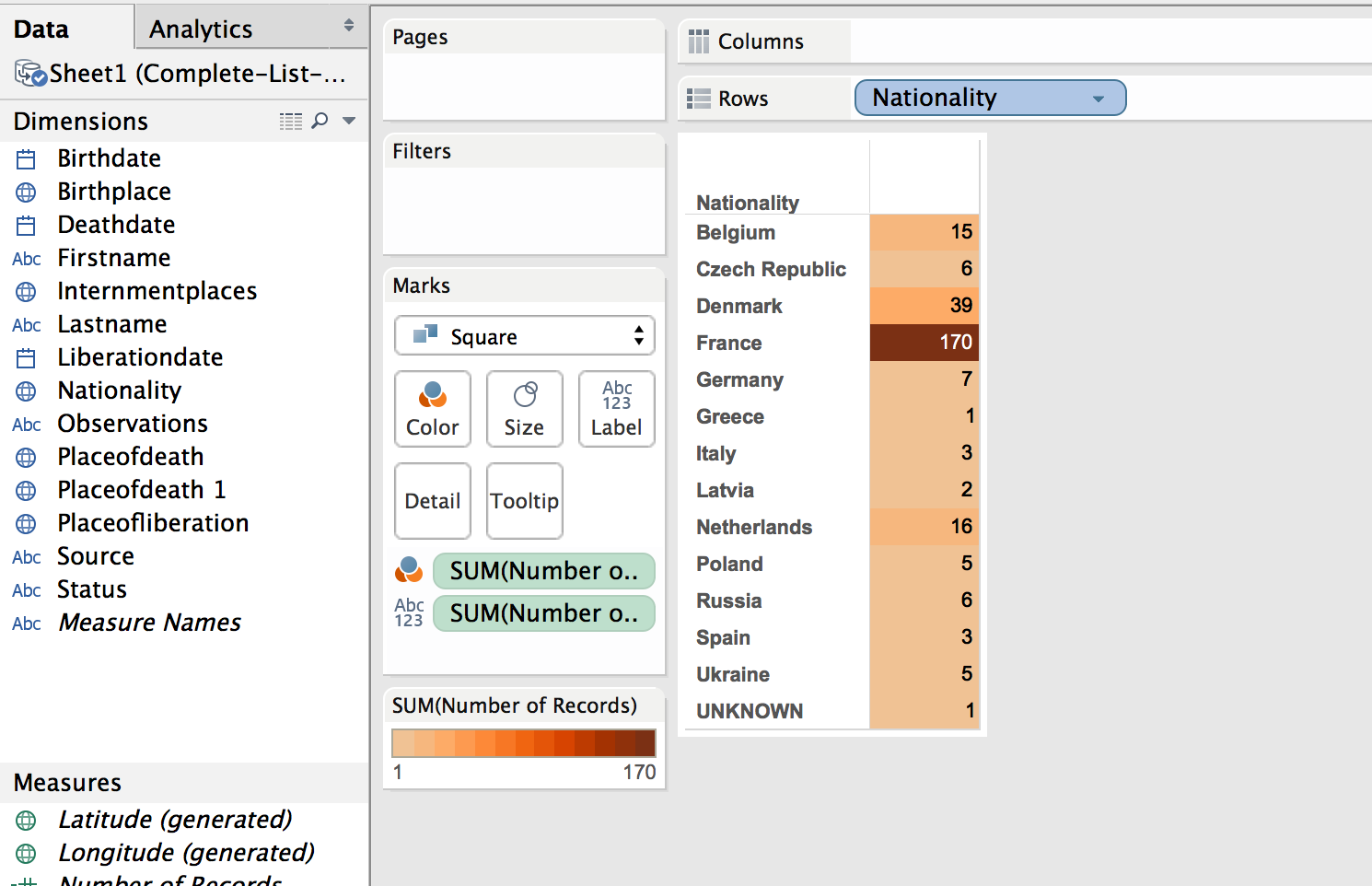
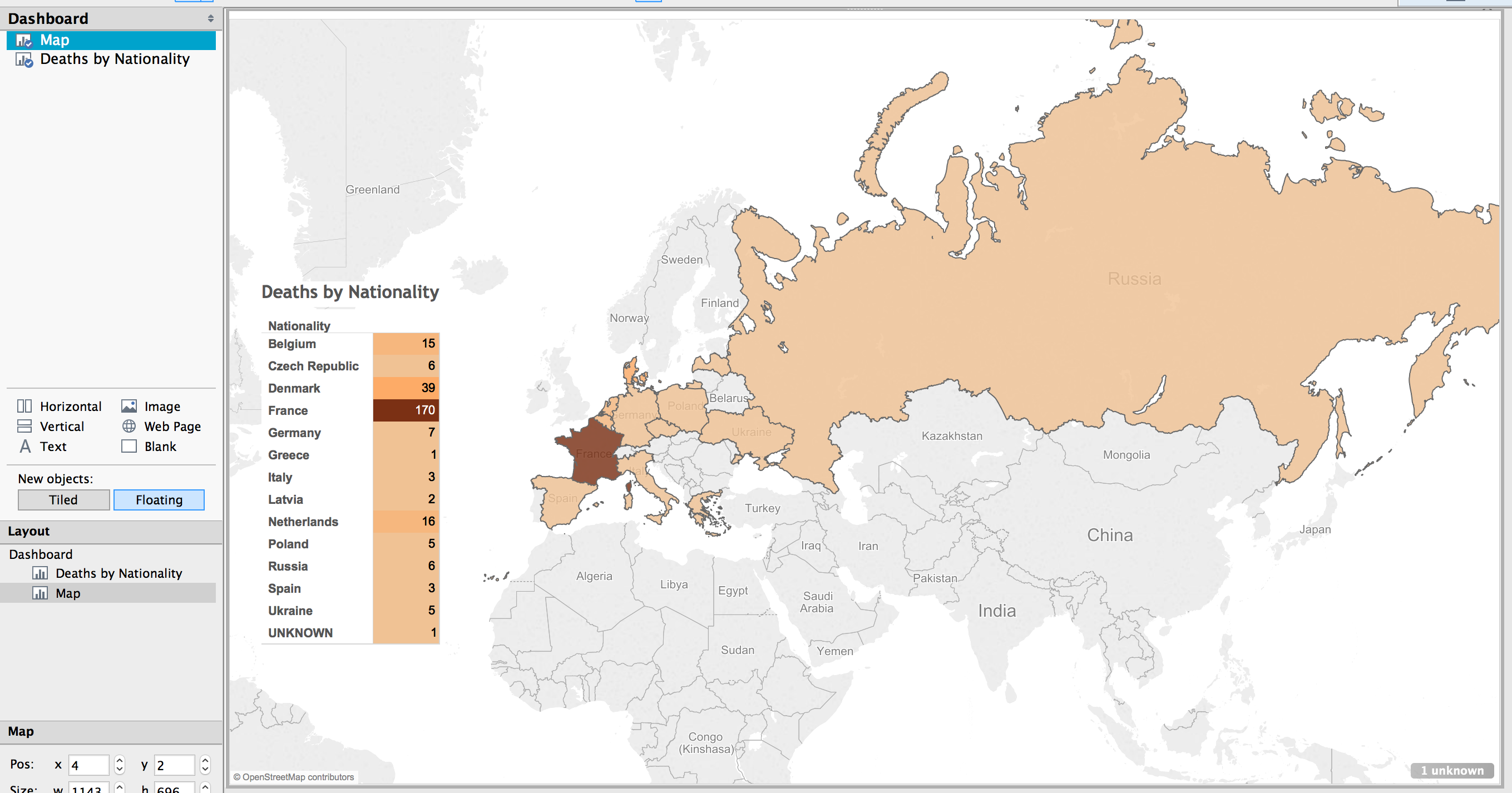
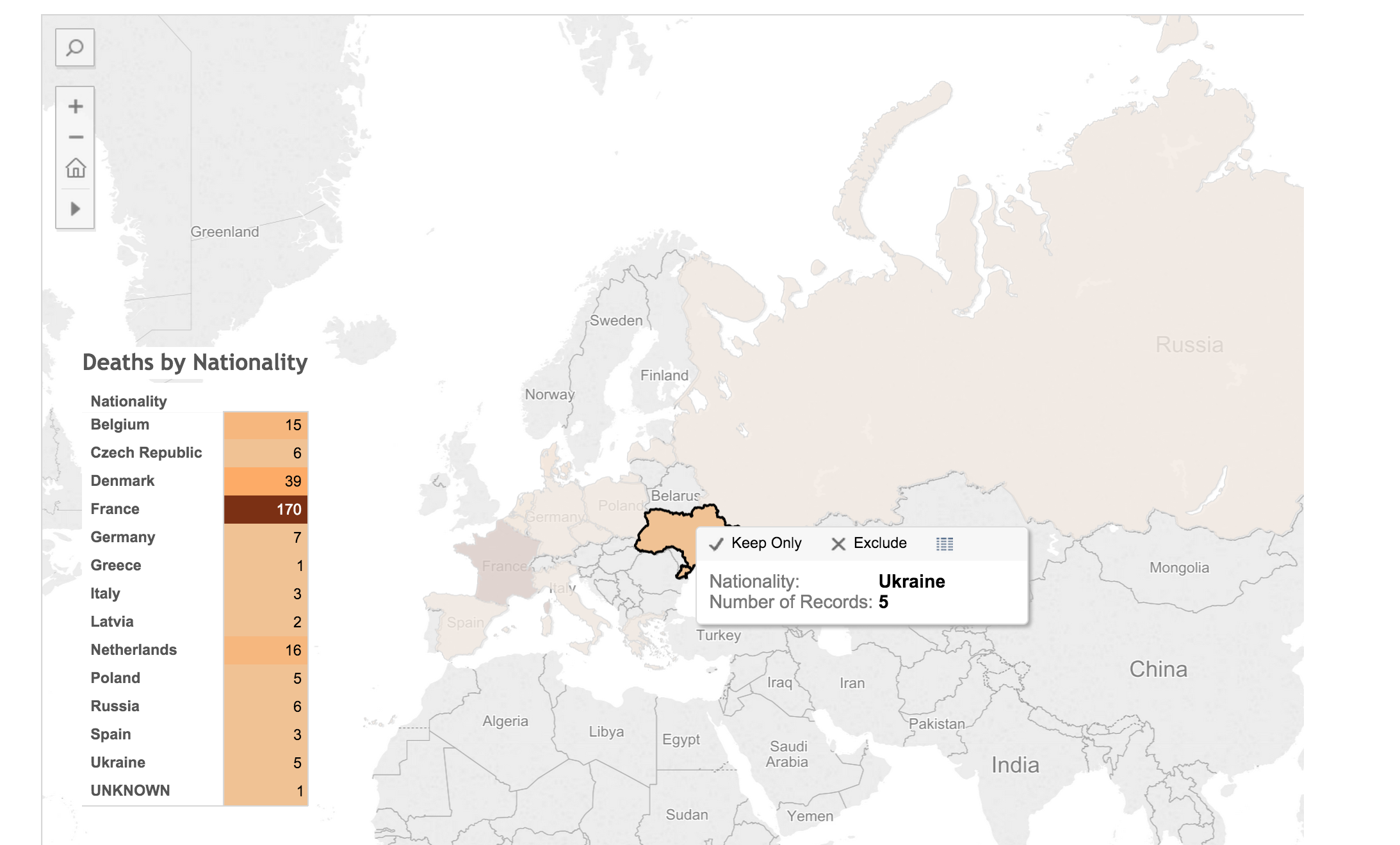
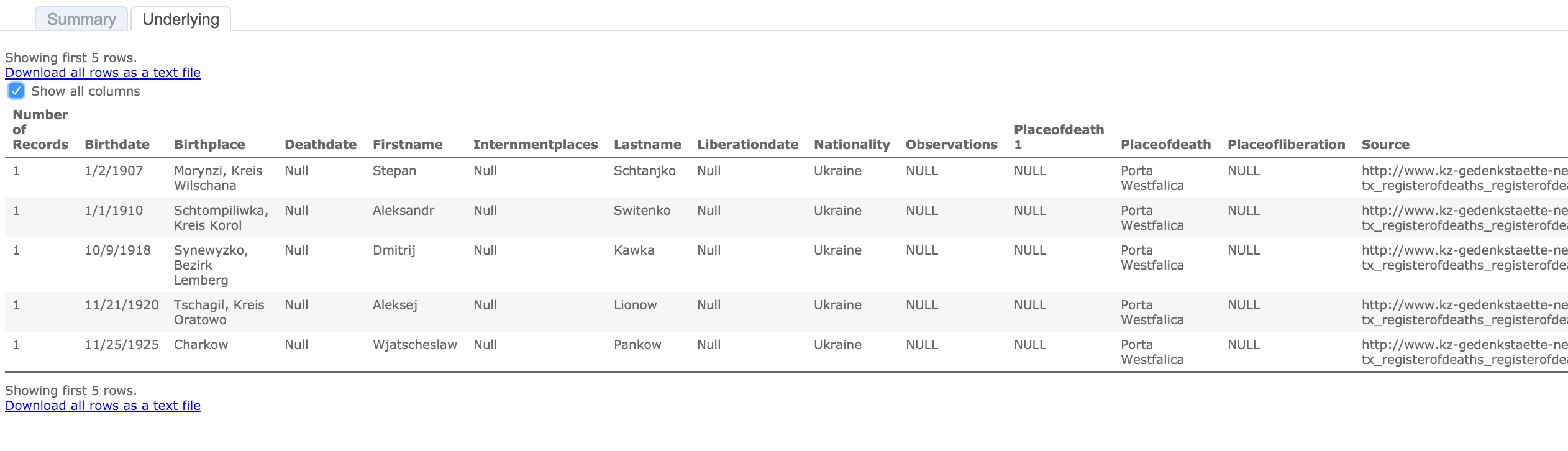
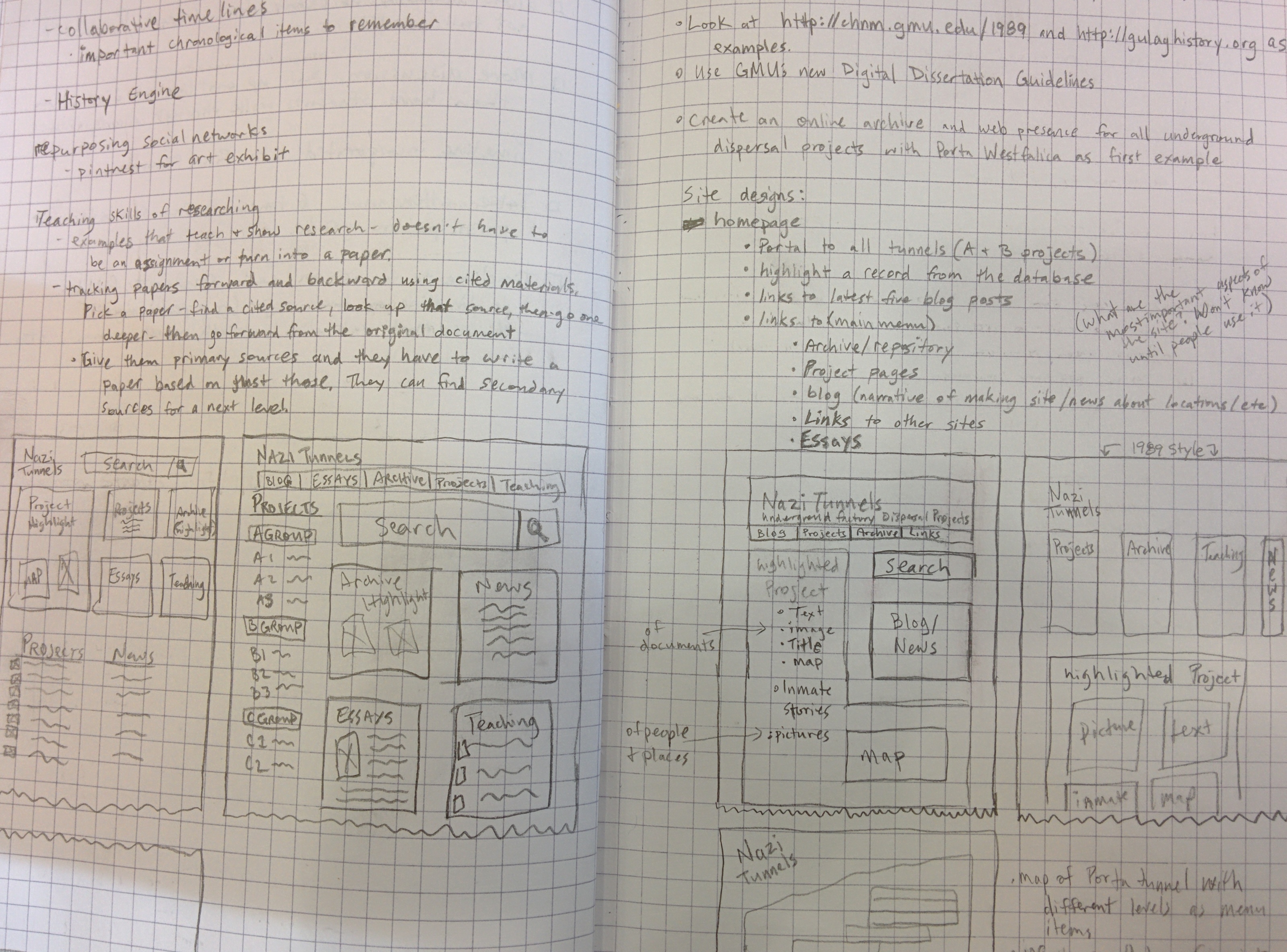
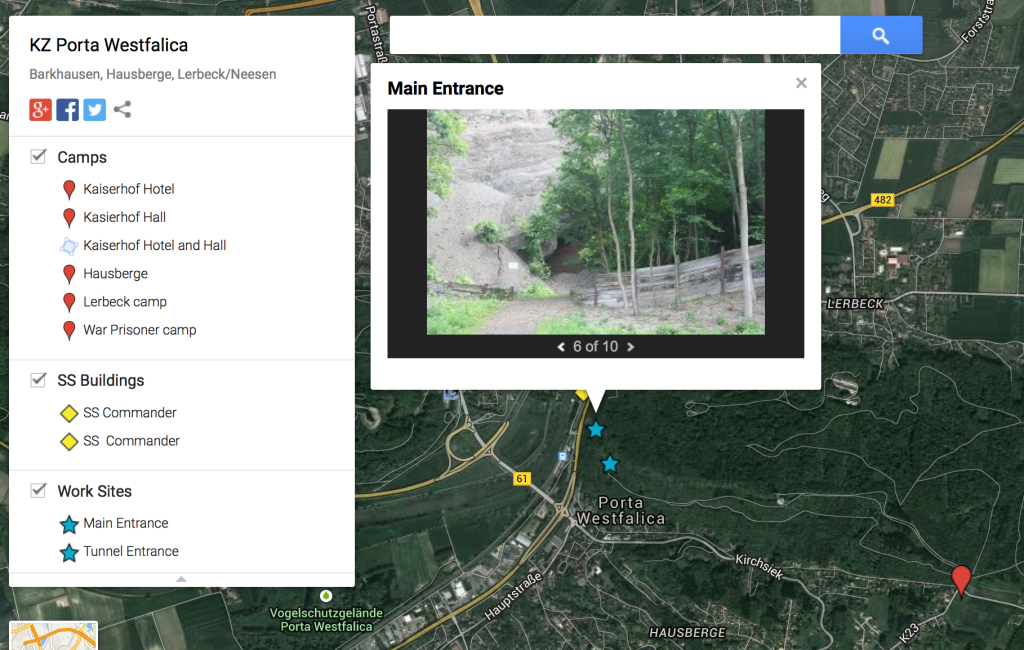
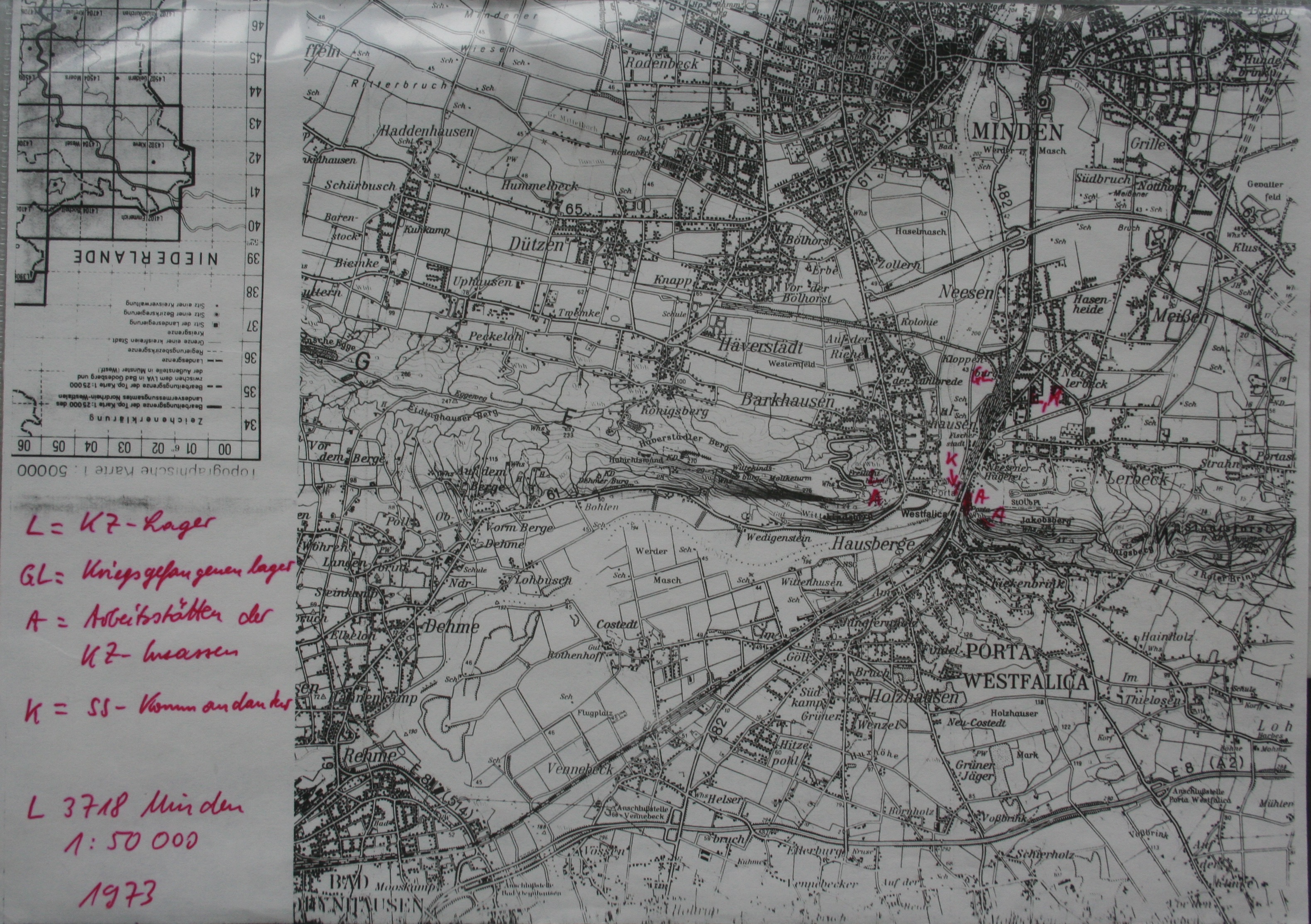
Scrivener to Markdown and HTML
How to write in Scrivener and display in HTML, Markdown, ODT, or Doc and keep the footnotes and images.
This is the process I use for getting my chapters out of Scrivener and formatted into Markdown and HTML for putting on the web. Markdown for Github, and HTML for a static website, and Doc for turning in to advisors and the Library.
Write it
Use Scrivener to bring all of the notes and sources together in one place.
Note it
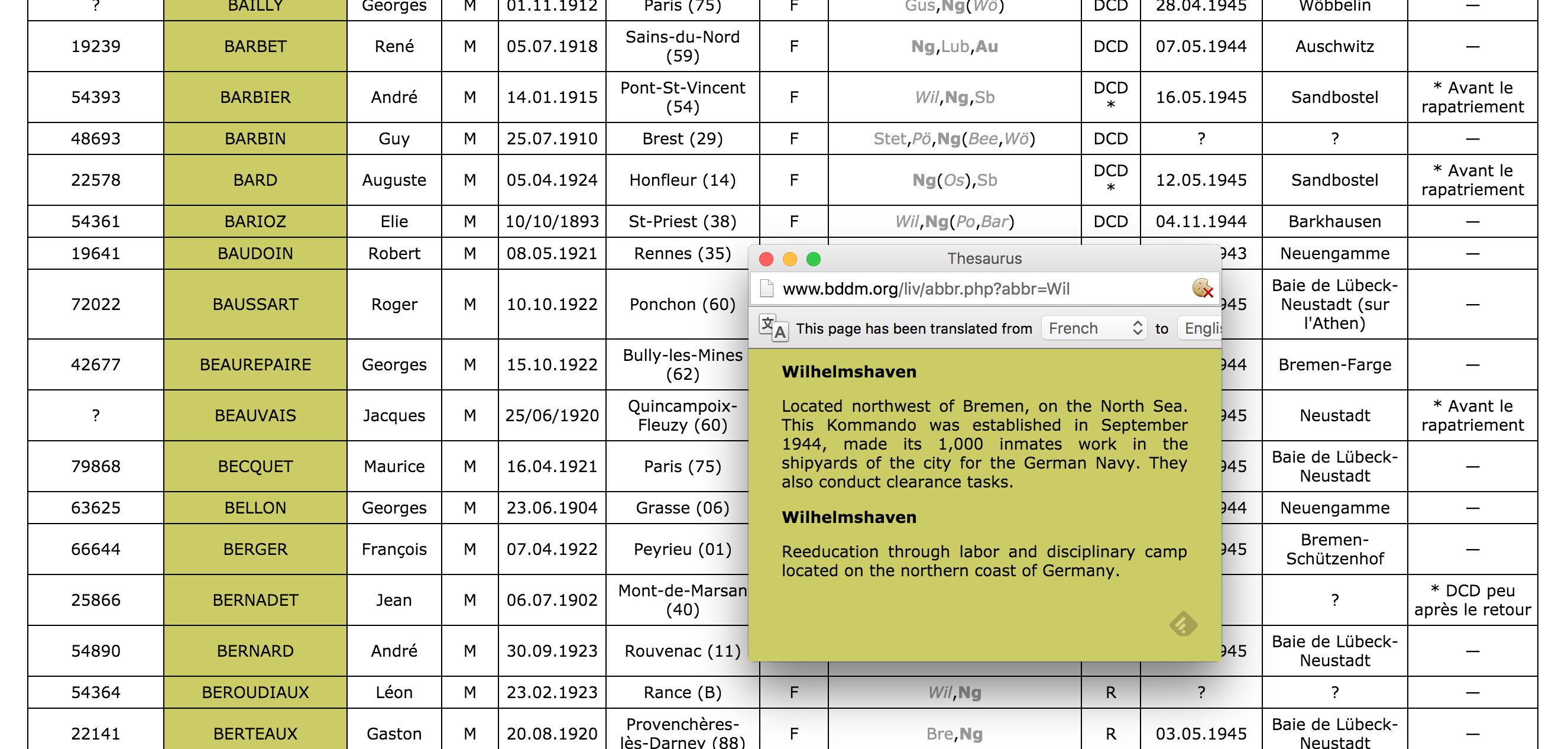
The process of writing actually begins while reading through books and looking at original source documents. For each source (whether book, document, image, or web page) I create an entry in Zotero. With an entry in Zotero, I create a child-note for that entry and take notes in that child-note. I always include the page number in the notes for easy referencing later. A typical note for an entry in Zotero looks like this:
Kaj Björn Karbo (July 4, 1920)
{ | Karbo, 1947 | | |zu:312:A6J3JADD}
page 1,
1400 men were supposed to wash in half and hour at 20 faucets.
Longest roll call was 4 hours because a couple of men had escaped.
page 2,
Relationship to Kapos was bad, also to Russians, and somewhat so to other nationalities.
Kapos were German, Russian, Polish and Czech
page 3,
Punishments consisted of beatings with boards from a bed and truncheon.
Stretched over a bench and held by four men and then beat
page 4,
Was part of many different work commands. In January 1945 was Schieber,
the lowest rung of prison hierarchy. He was in charge of a 16 man work
gang. they helped German civilian workers build a factory for synthetic fuel.
The part in curly braces { | Karbo, 1947 | | |zu:312:A6J3JADD} comes in handy later when adding citations in Scrivener.
Compose it
With all of the notes taken (for now, it can be a never ending process), copy and paste the relevant notes in the correct section of the Scrivener outline. Basically, each idea gets its own ‘page’. This boils down to each paragraph, more or less, on its own ‘page’.
Export it
First step is to export the chapter from Scrivener.
- Export it as the OpenOffice (.odt) format. Give it a name like
chapter2.odt.
Scan it
To get the footnotes into the correct format (MLA, Chicago, etc), we’ll scan the .odt file with Zotero. This creates a new file.
- Open Zotero, click the gear, and select ‘RTF/ODF Scan’.
- Select the file you created above (
chapter2.odt).
- Create a new name and place to save it (
chapter2-citations.odt)
Cite it
The Zotero scan converts all of the coded citations from Scrivener into ‘normal’ citations.
from this: { | Blanke-Bohne, 1984 | p. 16 | |zu:312:KMQEIBU0N}
to this: Blanke-Bohne, 1984.
To get it into a different citation style, we’ll open up the file in LibreOffice and change the citation style using the Zotero ‘Set Document Preferences’ menu.
from this: Blanke-Bohne, 1984.
to this: Blanke-Bohne, Reinhold. "Die unterirdische Verlagerung von Rüstungsbetrieben und die Aßuenlager des KZ Neuengamme in Porta Westfalica bei Minden." Dissertation, University of Bremen, 1984.
After the changes finish (could take a while), then save the document as a Word, make sure to do a ‘Save As’ .docx file (chapter2-citations.docx).
Fix it
Only the .docx format is supported by pandoc for extracting images, so we’ll need to use Word as the final format before converting to Markdown and HTML. Frankly, it also has much better grammar and spell checking.
Open the .docx in Microsoft Word and fix up any formatting issues.
I also turn this version in to my advisors for review.
Convert it
In the terminal, we’ll use the pandoc command to convert the file to Markdown and HTML.
This will convert the .docx file to a markdown file, extracting the images and putting them in a ‘files/media/’ directory.
The images are named incrementally in the order they are encountered in the document. The images are given a default name, keeping the extension. If I had four images in the file (two jpegs, one png, and one gif), they would be extracted and named like so: image1.jpeg, image2.jpeg, image3.png, image4.gif, etc.
We’ll have to go in and fix the tables and check for other formatting issues.
pandoc --smart --extract-media=files -f docx -t markdown_github chapter1-citations.docx -o chapter1.md
Next we can create an HTML file using pandoc and the .docx file.
pandoc --smart --extract-media=files --ascii --html-q-tags --section-divs -f docx -t html5 chapter1-citations.docx -o chapter1.html
This creates an HTML file with the images linked to the files in the files/media/ directory and the footnotes converted to hyperlinks.
Version it
Now these files can more easily be tracked with a versioning system, like git, and the HTML files can be uploaded for a static website version of the
dissertation. Styling can easily be applied if used in a Jekyll site.
For sharing on Github, there are two repos, main and gh-pages.
main repo
The main repo is simply the chapter directories with each of the document versions and the extracted media files. Once edits and conversions are done, this is updated with a simple
git add .
git commit -m "Updates chapter X"
git push
gh-pages repo
The gh-pages repo contains the files needed to convert the html version of the doucments into a Jekyll based static website. The trick here is to get all of the updates from the main repo into this gh-pages repo. This is accomplished with doing the following command while checked out in the gh-pages branch.
```
git checkout master -- chapterX
```
Before I can push the new changes to Github, I’ll need to fix a few things in the html version of the chapter.
First is to add some YAML front matter. I add this to the beginning of the HTML version.
---
layout: page
title: Chapter X
---
Second, update the path for the images so that they will work. I open the file in Vim and do a simple search and replace:
:%s/img src="files/img src="..\/files/g
Now I can update the gh-pages branch and the site.
git add .
git commit -m "Add updates from chapterX"
git push